Wer schon mit (Coding-)Agents experimentierte, kennt das beschwingende und erhebende Gefühl, das da durch die gerufenen Mächte mit Leichtigkeit etwas Komplexes, Funktionierendes und Wunderbares entsteht. Diese Technologie eröffnet beeindruckende Möglichkeiten. Jeder kann - ausgestattet mit etwas Neugier und Geduld - mit einem Agenten seiner Wahl (vordergründig simpel) 'Vibe-Coden' und seine Probleme lösen. Folgend soll auf den stets folgenden Realitätsabgleich mit nicht endenden, aber interessanten Problemen eingegangen werden.
Bei meinem ersten Coding-Projekt kam ich schnell an den Punkt einer schlaflosen Nacht mit Grübeleien, ob die Geheimnisse, die mein Projekt verarbeitet (z.B. API-Keys), sicher sind. Ob für den unwahrscheinlichen Fall, dass jemand anderes das Produkt einmal benutzt, ich genug getan habe um möglichen Schaden von dieser Person abzuhalten...
Die Grundfrage: Welche Techniken und Strategien helfen mir als Nicht-Coder, damit ein Coding-Agent trotz meiner überschaubaren Fähigkeiten seine Arbeit zu überprüfen, möglichst keinen Unsinn macht und sichereren Code erzeugt?
Daraus ist eine längere Recherche durch einige Rabbit-Holes geworden, daraus dann ein Modell, welches das Risikoszenario erfassen und in lösbare Teile zerlegen soll. Dieses Modell versuche ich hier in mehreren Beiträgen dar zu stellen:
- Teil 1 (dieser Beitrag): Wie bringe ich den Agenten dazu, möglichst sicheren und sinnvollen Code zu erzeugen? .. und wie kontrolliere ich das?
- Teil 2: Wie schütze ich meine persönlichen Daten und mein System vor dem Agenten?
- Teil 3: Wie schütze ich den Agenten?
Begriffe und Werkzeuge, die hier auftauchen — Diff, CI, Pre-Commit-Hook, Trust Boundary, Pattern-Completion, YOLO-Mode usw. — sind im Glossar kurz erklärt. Wer nicht aus dem Coding-Alltag kommt, liest den Beitrag mit dem Glossar im zweiten Tab.
1. Was diese Systeme wirklich tun und was sie nicht leisten
Bei mehr als oberflächlicher Nutzung von 'AI' wird man sich der Fehleranfälligkeit der Systeme recht schnell bewusst. Was Marketingstrateg:innen als "AI" oder "KI" labeln, sind tatsächlich 'nur' probabilistische Sprachmodelle (Large Language Modells /LLM's), die auf hohem Niveau Pattern-Completion betreiben und statistische Muster vervollständigen. Sie wissen nichts. Sie wollen nichts. Sie produzieren aus ihrem parametrischen Wissen heraus das wahrscheinlichste nächste Token.
Dass diese Modelle dabei regelmäßig halluzinieren und von der "Wahrheit" abweichen — sprich: Fehler machen — muss man bis auf weiteres als inhärentes Feature akzeptieren, als grundlegenden Teil ihrer Funktionsweise. Die daraus entstehenden Risiken sind bewusst & aktiv zu managen.
Daraus folgt unmittelbar:
- Halluzinationen sind Teil der Funktionsweise deines Systems. Die Häufigkeit lässt sich reduzieren, die Tatsache nicht.
- Dein Modell bzw. sein Output ist nicht vertrauenswürdig. Selbst wenn erzeugter Code läuft oder der Output plausibel aussieht, kann er verdeckt falsch sein — falsche Annahmen, falsche Trust Boundaries, falsche Defaults.
- Der Output sollte behandelt werden wie der Output jedes anderen statistischen Prozesses: kritisch — mit Stichproben, Gates, und der Annahme, dass ein Teil davon Slop ist.
Das ist also recht nah am echten Leben, daher Don't Panic! — da hilft nur Struktur und Disziplin.
2. Das Modell für die Erstellung von sicherem Code
Sicherheit herbeiprompten reicht nicht, es braucht mehrere Ebenen, die unterschiedlich wirken und die im besten Fall jeweils den Fehlermodus einer anderen Schicht abdecken.
| Schicht | Was es ist | Wirkmechanismus | Grenzen |
|---|---|---|---|
| 1. Agenten-Ethos | Werte und Prioritäten, die du dem Modell mitgibst - globale Regeln, projektspezifische Regeln, Session-Anker | Der Agent _will_ das Richtige tun | Greift nicht, wenn der Agent manipuliert, abgelenkt oder überfordert ist. |
| 2. Mechanische Gates | Werkzeuge, die objektiv messen - Linter, Type-Checker, Tests, Pre-Commit-Hooks, Secret-Scanner, CI | Der Prozess _darf_ Fehler nicht durchschieben | Greift nicht bei Logik- und Trust-Boundary-Fehlern, die kein Werkzeug erkennt |
| 3. Reversibilitäts-Design | Kleine Commits, eigene Branches, lesbare Diffs, Zweit-Review (Mensch oder Agent), einfache Rollbacks | 3rd-party Kontrolle; Schaden bleibt _klein und rückholbar_, wenn Schicht 1 und 2 nicht halten. | Greift nicht, wenn du selbst schnell und unaufmerksam mergst |
| 4. Kontext- & Informationshygiene | Kontrolle darüber, welche Informationen überhaupt in den Denkraum des Agenten gelangen | Das Modell arbeitet nur mit vertrauenswürdigem, relevantem und sauber getrenntem Kontext | Greift nicht, wenn falscher oder manipulierter Kontext bereits als vertrauenswürdig eingestuft wurde |
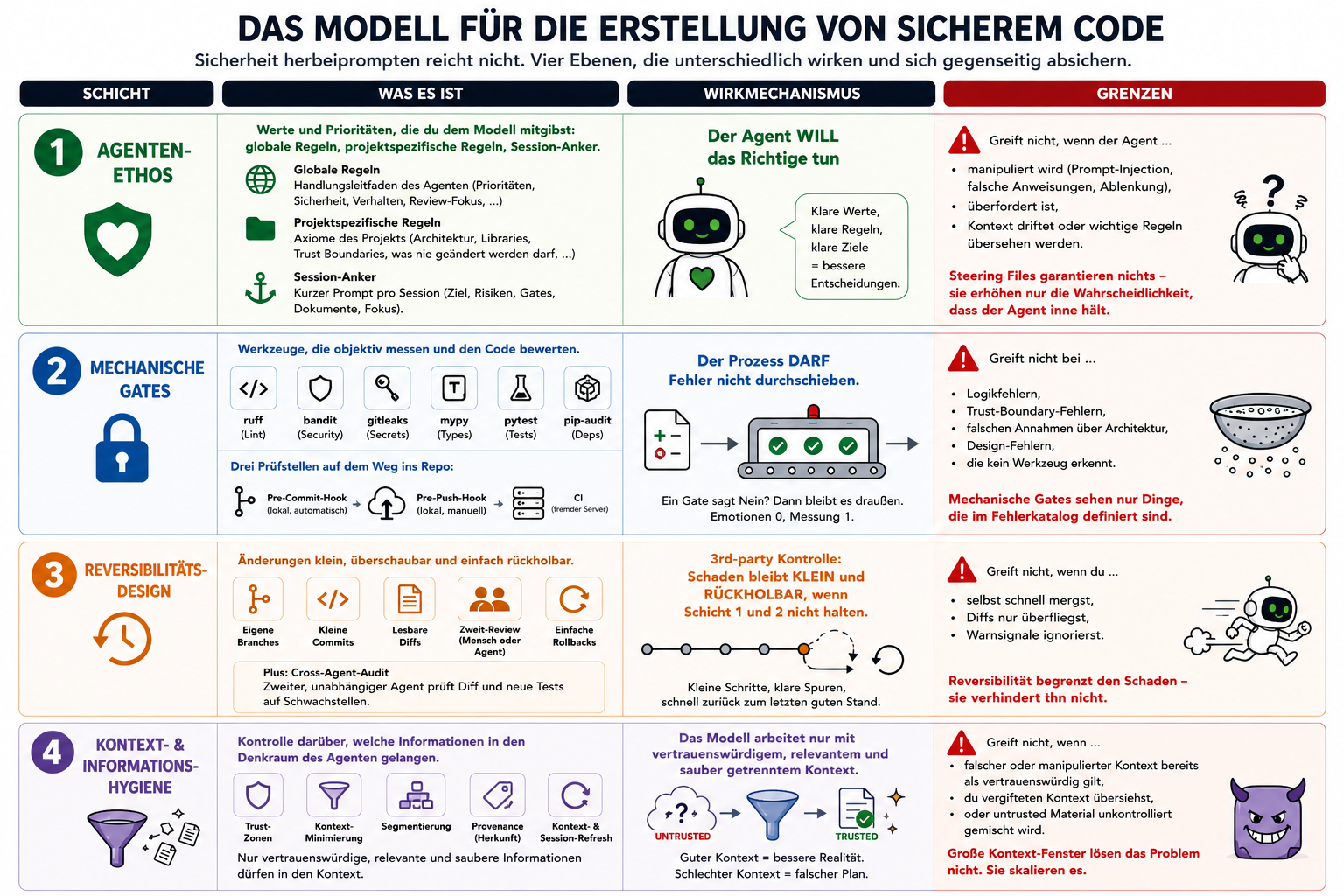
Schicht 1 — Arbeits-Ethos
Du kannst deinem Coding-Agenten über seine 'Steering Files' Prioritäten, Anweisungen und Weltanschauung mitgeben. Sie werden dem LLM am Anfang jeder Session in den Kontext geladen.
Je nach Anbieter heissen die Dateien CLAUDE.md, AGENTS.md oder .cursorrules [...] — Sie können genutzt werden, einem Sprachmodell so etwas wie berufliche Vorsicht beizubringen.
Es lohnt sich, das sorgfältig zu entwickeln!
Globale Regeln als Handlungsleitfaden des Agenten & was da m.E. nach rein sollte:
- Sicherheitsphilosophie: security > privacy > cost > usability (und usability ist NICHT unwichtig)
- Prioritäten: Sicherheit zuerst, dann Privatsphäre, dann Effizienz, zuletzt Komfort. Wenn es Zielkonflikte gibt, soll der Agent diese offen legen, Option vorschlagen und Trade-offs offen benennen.
- Grundhaltung: vorsichtiger Senior Engineer statt autonomer Cowboy. Kleine, sichere, nachvollziehbare Änderungen mit minimalem Blast Radius.
- Misstrauensmodell: Maschine, Terminal, Env Vars, Clipboard, Repo, History und externe Inputs gelten grundsätzlich als sensibel oder untrusted.
- Kommando- und Workspace-Sicherheit: keine destruktiven Befehle ohne explizite Freigabe, keine stillen Massenänderungen, keine ungeprüften Remote-Skripte, keine fremden Änderungen überschreiben.
- Secret- und Privacy-Disziplin: Secrets niemals ausgeben, weiterreichen, einbauen oder loggen.
- Secure Coding Rules: untrusted input validieren, fail closed, least privilege, Security-Checks nah an die sensible Aktion.
- Review-Fokus: zuerst Leaks, Auth/AuthZ, Injection, unsichere Subprozesse/Netz/File-Operationen, Race Conditions und Supply-Chain-Risiken.
- Dependencies: möglichst wenige neue Abhängigkeiten, bevorzugt vertrauenswürdige und auditierbare Pakete.
- Git-/Change-Control: keine History-Rewrites, keine Force-Aktionen ohne Auftrag, Commits klein und reviewbar halten.
- Verhaltensregel: bei Unsicherheit nicht bluffen, sondern Risiken, Annahmen und Prüfbedarf offenlegen.
- Rahmenwerke: gedanklich an OWASP, SSDF, SLSA/Sigstore orientiert, ohne daraus ein Bürokratiemonster zu machen.
Projektspezifische Regeln — via projektspezifischem 'Steering File', das sich mit dem Projekt entwickelt. (Auch hier hängt der Dateiname am Werkzeug; CLAUDE.md, AGENTS.md, .cursorrules u.a.). Inhaltlich stehen hier die Axiome dieses Projekts:
- was nie geändert werden darf
- welche Architektur-Entscheidungen festliegen
- welche Bibliotheken bevorzugt werden
- welche Trust Boundaries existieren...
Session-Anker — auch 'Starter-Prompt' am Anfang jeder Arbeitssession. Er gibt dem Agenten zu Beginn einer Sitzung einen klaren Arbeitsrahmen. Er definiert Ziel, Scope, Prioritäten, wichtige Quellen und die gewünschte Arbeitsweise. So bleibt die Arbeit konsistent, fokussiert und thematisch sauber getrennt, statt dass die AI Aufgaben, Rollen oder Kontexte vermischt.
Modelle haben kein langfristiges Gedächtnis zwischen Sessions, und auch innerhalb einer Session driftet die Aufmerksamkeit. Der Anker ist die Wiederholung, die das verhindert.
Kurz gesagt: Mittels Steering-Files versuchen wir, aus einem sehr überzeugenden Autocomplete einen halbwegs paranoiden und strukturiert vorgehenden Infrastruktur-Agenten zu machen.
Grenzen: 'Steering Files' garantieren nichts. Sie erhöhen nur die Wahrscheinlichkeit, dass der Agent innehält, bevor er mit voller Überzeugung etwas Unvorteilhaftes tut. Sie unterliegen im Kontext der Drift und können durch eine falsche Zeile Text im Chat unwirksam werden.
Schicht 2 — Mechanische Gates
Die zweite Schicht misst nach festen Regeln. Jeder Diff (Änderung im Code) läuft durch Werkzeuge, die unabhängig vom Agenten arbeiten und den Code bewerten nach unterschiedlichen Kriterien.
Bei mir (python Projekt) hat sich dieses Test-Set ergeben:
Manuell - In jeder Iteration Funktionen und Fehlerzustände der Software testen. Der Agent deines Vertrauens erstellt ganz gute Test-Sequenzen.
& automatische Tests:
ruff(Lint). Markiert offensichtlich kaputte oder unsaubere Stellen.bandit(statische Sicherheitsanalyse). Spezialisierter Scanner, der Code nach bekannten und typischen Sicherheitsfallen absucht.detect-secrets,gitleaks(Secret-Scanner). Suchen im Diff nach API-Schlüsseln, Tokens und Passwörtern.mypy,pyright(Type-Checker). Eine "passt das überhaupt zusammen"-Prüfung, die z.B. merkt, wenn eine Funktion, die eine Zahl erwartet, mit einem Text aufgerufen wird.pytest,hypothesis(Test-Suite). Die eigentliche Funktionsprüfung: kleine Programme, die Erwartungen formulieren und prüfen, was der Code zurückgibt.hypothesisspeziell für Property-Tests, die mit zufälligen Eingaben nach Gegenbeispielen suchen — besonders wertvoll bei Code, der unkontrollierten Input verarbeitet (Parser, Validatoren).pip-audit(Dependency-Audit). Ein Abgleich der installierten Pakete gegen eine Datenbank bekannter Sicherheitslücken.
Wer triggert das? Moderne Coding-Agenten testen und linten oft selbst.
Aber verlass dich nicht auf deinen Agenten.
Verlässlich wird es erst durch Eintrag in eine der Steering Files ("vor und nach jeder Änderung Tests laufen lassen") und Kontrolle.
Drei Prüfstellen auf dem Weg von meinem Rechner ins öffentliche Repository: Pre-Commit, Pre-Push, CI
- Pre-Commit-Hook (lokal, automatisch) — bevor eine Änderung aufgenommen wird.
- Pre-Push-Hook (lokal, manuell, nativ in Git) — bevor die gespeicherten Änderungen das eigene Gerät verlassen und in das entfernte Repository gepusht werden. Hier laufen teurere Prüfungen über alle noch nicht gepushten Commits, die volle Test-Suite.
- CI (fremder Server beim Anbieter deines Vertrauens) — sobald der Code beim Anbieter (z.B. GitHub) ankommt, läuft dieselbe Prüfung ein drittes Mal.
Grenzen: Mechanische Gates sehen nur Dinge, die im Fehlerkatalog definiert sind. Sie finden kaputte Syntax — aber nicht unbedingt kaputte Architektur.
Wie ich beurteile, ob die Tests etwas wert sind
Eine Vielzahl existierender Test gibt es aus Gründen, aber neue Tests vom Agenten erstellen und laufen lassen ist eine Sache, ihren Wert beurteilen eine andere — und für Nicht-Coder die schwerere.
- Cross-Agent-Audit auf die Tests selbst (siehe Schicht 3): "Lies diese Test-Datei. Welche Sicherheitsanforderungen werden hier nicht geprüft? Welche Tests testen, was ihr Name behauptet, und welche nicht?..."
- Coverage als grobes Maß. Werkzeuge wie
pytest-covzeigen, welcher Anteil des Codes überhaupt von Tests berührt wird. 80%+ ist ein üblicher Schwellwert. Aber: hohe Coverage mit oberflächlichen Tests mag ein falsches Sicherheitsgefühl erzeugen. - Fehler einbauen. Kommentiere eine kritische Zeile aus (z.B. den Aufruf des Secret-Detektors), und schau wie sich das auf die Ergebnisse auswirkt. Diese Methode heißt Mutation Testing; manuell und punktuell ist sie auch für Nicht-Coder machbar.
Schicht 3 — Reversibilität & Zweit-Review
Hier entscheidet sich, wie groß der Schaden wird, wenn die vorigen Schichten nicht gehalten haben.
Änderungen müssen klein, überschaubar/auditierbar und einfach zurück zu bauen sein. Das heisst zunächst, alles in kleine Teilaufgaben zu zerlegen, die in einer Session erledigt werden können, ohne dass eine compaction den Kontext verdreht (-> siehe Schicht 4).
Zum verfolgen der Änderungen am Projelt benutzt man am besten git.
Und dann, der für mich wichtigste Schritt für Garagen-Projekte ohne menschlichen Code-Review-Partner:
- Cross-Agent-Audit. Ein zweiter, unabhängiger Agent — anderes Modell, andere Trainingsdaten — bekommt den Auftrag, die Änderung (Diff) zu überprüfen und Schwachstellen zu finden.
- Cross-Agent-Audit nicht nur auf den Code, sondern auch auf neue Tests anwenden.
Grenzen: Auch für den Auditor-Agenten gilt: er kann und wird Fehler machen.
Schicht 4 — Kontext- & Informationshygiene
Ein Agent kann einen guten Ethos eingepflanzt haben, alle Tests bestehen, saubere Commits schreiben — und trotzdem Unsinn produzieren, wenn sein Kontext mit den falschen Sachen angereichert ist. (Lethal Trifecta und Prompt-Injection sind in diesem Kontext wichtige Begriffe, auf die dank ihres Bedeutungsumfanges gesondert eingegangen werden muss.) LLMs sind kontext-sensitiv: ein einziger Satz, der ihnen ins Sichtfeld gerät, kann Prioritäten verschieben. ...und auf einmal erscheint ihm Sabotage wie Best Practice.
Das ist ein Routine- und Disziplin-Thema (Eigentlich Teil von Schicht 1 — aber so wichtig, dass ich sie als eigene Disziplin behandle.) um die Kontrolle über das, was der Agent zum Arbeiten in seinen Kontext bekommt.
Es braucht:
- Trust-Zonen. Trusted: Meine selbst erstellte und geprüfte Architektur-Doku. Untrusted: ein zufälliges Markdown aus dem Netz.
- Kontext-Minimierung. Mit grundsätzlichem Minimalansatz NUR die Information ins Sichtfeld geben, die der Agent für die aktuelle Aufgabe wirklich braucht.
- Segmentierung. Vertrauenswürdiges und unvertrauenswürdiges Material getrennt halten. Agenten vor letzterem schützen.
- Provenance (Herkunftsnachweis). Woher kommt dieser Auszug? Wann zuletzt geprüft? Von wem?
- Regelmäßiger Kontext- und Session-Refresh. Was der Agent vor der letzten compaction erhahren hat, unterliegt der Bedeutungsdrift. Und anscheinend werden nicht alle Bereiche eines langen Kontextes gleich gewichtet. --> Vor wichtigen Entscheidungen: Frischkontext geben, alten verwerfen. Regelmässig neue Sessions starten.
Ach ja: Große Kontext-Fenster lösen das Problem nicht. Sie skalieren es.
Grenzen: Die eigene Disziplin. Wenn vergifteter Kontext übersehen wird oder bereits als vertrauenswürdig gilt, baut der Agent nach falschen Prämissen.
3. Checkliste
Was ich vor jedem Projekt aufbaue und vor/während jeder Session prüfe:
- Globale Regel-Datei sauber formuliert und aktiv? (Werte, Prioritäten, Defaults stehen.)
- Projektregeln im Repo aktiv und Projektstruktur sauber aufgesetzt? (Was darf rein/ was nicht. Worauf stützt sich der Agent in seiner Arbeit?)
- Session-Anker am Anfang gesetzt? (Was steht heute an, welche Gates gelten.)
- Pre-Commit-Hooks & Pre-Push-Hooks definiert und eingerichtet?
- Tests laufen grün, bevor der Agent anfängt?
- Branch frisch, klein, fokussiert? (Kein "Sammel-Branch" für drei verschiedene Aufgaben.)
- Release-Gate abgearbeitet vor Commit und Push?
- Bei sicherheitsrelevanten Änderungen sofort, sonst regelmässig: zweiter Agent dran?
Nächste Beiträge
- Teil 2: Wie schütze ich mein System und meine Daten vor dem Agenten? — Sandboxing, Tool-Permissions, dedizierter Workspace, was ein Agent darf und was nicht.
- Teil 3: Wie schütze ich den Agenten? — Indirekte Prompt-Injection, untrusted Input, die finstere Trifecta.
Info
Ich bin weder Entwickler noch Security-Profi und habe das Coden hinter mir gelassen, als man für Websites sein JavaScript noch selber schreiben musste. Nun sind wir auf einmal in der Ära der agentischen Assistenten, und als neugieriger Bastler versuche ich, diese Systeme stilvoll in meinen Alltag einzubauen. Unter anderem entwickle ich eine Software, um eins meiner Probleme zu lösen — eine TUI, die rund um eine echte Shell erklärt und warnt und mich davon abhält, mein System zu zerstören :-) Was da oben steht , ist ein iterativer, feedbackfähiger Schutzrahmen für ein autonom gebautes Garagen-Projekt — gewachsen aus Recherche, Diskussionen und vielen Fehlern. Korrekturen willkommen.
Kein Anspruch auf Vollständigkeit, Korrektheit oder Erleuchtung. Du siehst hier meinen Lernprozess — work in progress. Korrekturen und Widerspruch sind herzlich willkommen (E-Mail im Impressum). Dieser Beitrag lebt. Was heute gilt, ist morgen vielleicht schon Nostalgie.